機械学習メモ
機械学習メモ
This project is maintained by kino-3
敵対的生成ネットワークの原論文
参考文献
論文
Generative Adversarial Networks
https://arxiv.org/abs/1406.2661
コード
https://github.com/goodfeli/adversarial
理論
概要
- 生成モデル $ G $ : 訓練データ $ x $ の分布を再現し, $ D $ が誤識別する確率の最大化を目標とする。
- 識別モデル $ D $ : 入力 $ x $ が (生成モデルから生成されたものではなく) 訓練データである確率 $ y $ を推定する。$ D $ が誤識別する確率の最小化を目標とする。
これらの相反する目標を持った 2 つのモデルを同時に訓練する。
全体像
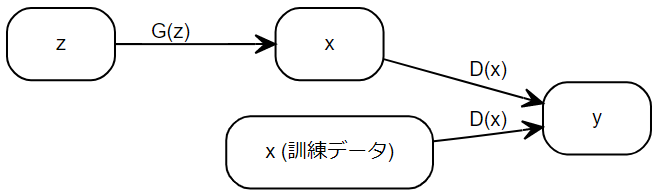
- 生成モデル $ G(z;\theta_g) $ , 識別モデル $ D(x;\theta_d) $ はともに多層パーセプトロンである。
- 生成モデルの入力 $ z $ は, 正規分布や一様分布である $ p_z(z) $ からサンプリングされたノイズ である。
- 識別モデルの出力 $ y=D(x;\theta_d) $ は $ [0,1] $ の範囲のスカラ―である。
- 正解ラベルは, $ x $ が訓練データのとき $ y=1 $ であり, $ x $ が生成モデルの出力 $ x=G(z;\theta_g) $ のとき $ y=0 $ である。
- 目的関数は次式で表される交差エントロピーの期待値に $ -2 $ を掛けた値とする。
- 識別モデルが $ y=0\,(i.e.\,1-y=1)$ であると判定した確率が $ 1-D(x;\theta_d) $ となるため。
よって, 目的関数は $ x $ と $ y $ の同時分布を $ p(x,y) $ とすると次のように表せる。ただし, $ (*) $ では以下を適用した。
- 訓練データ $ x $ の分布を $ p_{data}(x):= p(x\mid y=1) $ と表す。
- 生成モデルの出力 $ x=G(z;\theta_g) $ の分布を $ p_g(x):= p(x\mid y=0) $ と表す。
- 識別モデルに与えられる $ x $ のラベルには偏りがないと仮定して, $ p(y=0) = p(y=1) = \frac{1}{2} $ とする。
よって, $ \underset{G}{\min} \underset{D}{\max} V(D, G) $ となる $ \theta_g $ と $ \theta_d $ を求めればよい。
アルゴリズム
- ミニバッチ勾配降下法 (+ モメンタム法) を用いてパラメータを更新する。
- 「$ \theta_d $ の更新を $ k $ ステップ行った後, $ \theta_g $ の更新を 1 ステップ行う」という操作を反復する。
- $ k $ はハイパーパラメータである。各反復において, $ \theta_g $ が十分小さく変化する限り, $ \theta_d $ は最適解の付近に保たれる。
$ (**) $ より, バッチサイズを $ m $ とすると, $ \theta_d $, $ \theta_g $ は次の勾配に基づいて更新される。ただし, $ x^{(i)} $ は訓練データから取り出され, $ z^{(i)} $ は $ p_z(z) $ に従うノイズである。
\[\begin{aligned} & \nabla_{\theta_d} \frac{1}{m}\sum_{i=1}^{m}[\ln{D(x^{(i)})}+\ln{(1-D(G(z^{(i)})))}]\\ & \nabla_{\theta_g} \frac{1}{m}\sum_{i=1}^{m}[\ln{(1-D(G(z^{(i)})))}] \end{aligned}\]ただし, $ \ln{D(x^{(i)})} $ は $ \theta_g $ に依存しないことを利用した。
注意点: 初期段階の $ \theta_g $ の更新
$ \theta_g $ は $ \nabla_{\theta_g} \frac{1}{m}\sum_{i=1}^{m}[\ln{(1-D(G(z^{(i)})))}] $ で更新されるが, 更新の初期段階において, 生成器の出力 $ x = G(z; \theta_g) $ は明らかに訓練データと異なるため, $ z $ によらず $ D(G(z))\cong 0 $ となる。よって, $ \ln{(1-D(G(z)))} \cong 0 $ となり, この勾配は消失する。
これを回避するために, $ \theta_g $ の更新の初期段階では $ \ln{(1-D(G(z)))} $ を最小化するのではなく, $ \ln{D(G(z))} $ を最大化するとよい。($ \underset{\theta_g}{\rm argmin}\ln{(1-D(G(z)))} = \underset{\theta_g}{\rm argmax}\ln{D(G(z))} $ なので, この考え方は妥当である。)
$ \theta_g $ が最適解に収束したとき $ D_G^*(x) = \frac{p_{data}(x)}{p_{data}(x)+p_g(x)} $ となることの証明
$ a, b, y \in(0,1) $ のとき, $ a, b $ によらず, $ a\ln{y} + b\ln{(1-y)} $ は
\[\begin{aligned} & \frac{\partial}{\partial y} \left\{a\ln{y} + b\ln{(1-y)}\right\} = 0\\ & \Leftrightarrow \frac{a}{y}-\frac{b}{1-y}=0\\ & \Leftrightarrow y = \frac{a}{a+b} \end{aligned}\]のときに最大となる。これを $ (*) $ に適用すると題意は示される。
$ \underset{G}{\min} \underset{D}{\max} V(D, G) $ のとき $ p_g=p_{data} $となることの証明
$ (*) $ より, $ \tilde{p}(x) := \frac{p_{data}(x)+p_g(x)}{2} $ とすると, $ \int \tilde{p}(x) dx = 1 $ かつ $ \tilde{p}(x) \geq 0$ であるから,
\[\begin{aligned} \underset{G}{\min} \underset{D}{\max} V(D, G) &= \underset{G}{\min} \underset{D}{\max} \int p_{data}(x)\ln{D(x)}+ p_g(x)\ln{\left\{1-D(x)\right\}}dx\\ &= \underset{G}{\min} \int p_{data}(x)\ln{D_G^*(x)}+ p_g(x)\ln{\left\{1-D_G^*(x)\right\}}dx\\ &= \underset{G}{\min} \int p_{data}(x)\ln{\frac{p_{data}(x)}{p_{data}(x)+p_g(x)}}+ p_g(x)\ln{\left\{\frac{p_g(x)}{p_{data}(x)+p_g(x)}\right\}}dx\\ &= \underset{G}{\min} \int p_{data}(x)\left(\ln{\frac{p_{data}(x)}{\tilde{p}(x)}}-\ln{2}\right)+ p_g(x)\left(\ln{\frac{p_g(x)}{\tilde{p}(x)}}-\ln{2}\right)dx\\ &= \underset{G}{\min} -2\ln{2} + KL(p_{data}\parallel \tilde{p}) + KL(p_g\parallel \tilde{p}) \end{aligned}\]となる。よって, 生成モデル $ G $ が十分に柔軟であれば,
\[\begin{aligned} & p_g=p_{data}\\ & \Leftrightarrow p_g=\tilde{p}=p_{data}\\ & \Leftrightarrow KL(p_{data}\parallel \tilde{p})=0 \wedge KL(p_g\parallel \tilde{p})=0\\ & \Leftrightarrow\underset{G}{\min} \underset{D}{\max} V(D, G)\end{aligned}\]となる。